Historically, Panda has always run single-core. And even though the Panda3D codebase has been written to provide true multithreaded, multi-processor support when it is compiled in, by default we’ve provided a version of Panda built with the so-called “simple threads” model which enforces a single-core processing mode, even on a multi-core machine. But all that is changing.
Beginning with the upcoming Panda3D version 1.8, we’ll start distributing Panda with true threads enabled in the build, which enables you to take advantage of true parallelization on any modern, multi-core machine. Of course, if you want to use threading directly, you will have to deal with the coding complexity issues, like deadlocks and race conditions, that always come along with this sort of thing. And the Python interpreter is still fundamentally single-core, so any truly parallel code must be written in C++.
But, more excitingly, we’re also enabling an optional new feature within the Panda3D engine itself, to make the rendering (which is all C++ code) run entirely on a sub-thread, allowing your Python code to run fully parallel with the rendering process, possibly doubling your frame rate. But it goes even further than that. You can potentially divide the entire frame onto three different cores, achieving unprecedented parallelization and a theoretical 3x performance improvement (although, realistically, 1.5x to 2x is more likely). And all of this happens with no special coding effort on your part, the application developer–you only have to turn it on.
How does it work?
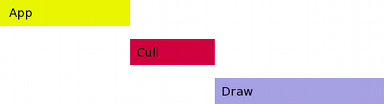
To use this feature successfully, you will need to understand something about how it works. First, consider Panda’s normal, single-threaded render pipeline. The time spent processing each frame can be subdivided into three separate phases, called “App”, “Cull”, and “Draw”:

In Panda’s nomenclature, “App” is any time spent in the application yourself, i.e. your program. This is your main loop, including any Python code (or C++ code) you write to control your particular game’s logic. It also includes any Panda-based calculations that must be performed synchronously with this application code; for instance, the collision traversal is usually considered to be part of App.
“Cull” and “Draw” are the two phases of Panda’s main rendering engine. Once your application code finishes executing for the frame, then Cull takes over. The name “Cull” implies view-frustum culling, and this is part of it; but it is also much more. This phase includes all processing of the scene graph needed to identify the objects that are going to be rendered this frame and their current state, and all processing needed to place them into an ordered list for drawing. Cull typically also includes the time to compute character animations. The output of Cull is a sorted list of objects and their associated states to be sent to the graphics card.
“Draw” is the final phase of the rendering process, which is nothing more than walking through the list of objects output by Cull, and sending them one at a time to the graphics card. Draw is designed to be as lightweight as possible on the CPU; the idea is to keep the graphics command pipe filled with as many rendering commands as it will hold. Draw is the only phase of the process during which graphics commands are actually being issued.
You can see the actual time spent within these three phases if you inspect your program’s execution via the PStats tool. Every application is different, of course, but in many moderately complex applications, the time spent in each of these three phases is similar to the others, so that the three phases roughly divide the total frame time into thirds.
Now that we have the frame time divided into three more-or-less equal pieces, the threaded pipeline code can take effect, by splitting each phase into a different thread, so that it can run (potentially) on a different CPU, like this:
Note that App remains on the first, or main thread; we have only moved Cull and Draw onto separate threads. This is important, because it means that all of your application code can continue to be single-threaded (and therefore much easier and faster to develop). Of course, there’s also nothing preventing you from using additional threads in App if you wish (and if you have enough additional CPU’s to make it worthwhile).
If separating the phases onto different threads were all that we did, we wouldn’t have accomplished anything useful, because each phase must still wait for the previous phase to complete before it can proceed. It’s impossible to run Cull to figure out what things are going to be rendered before the App phase has finished arranging the scene graph properly. Similarly, it’s impossible to run Draw until the Cull phase has finished processing the scene graph and constructing the list of objects.
However, once App has finished processing frame 1, there’s no reason for that thread to sit around waiting for the rest of the frame to be finished drawing. It can go right ahead and start working on frame 2, at the same time that the Cull thread starts processing frame 1. And then by the time Cull has finished processing frame 1, it can start working on culling frame 2 (which App has also just finished with). Putting it all in graphical form, the frame time now looks like this:

So, we see that we can now crank out frames up to three times faster than in the original, single-threaded case. Each frame now takes the same amount of time, total, as the longest of the original three phases. (Thus, the theoretical maximum speedup of 3x can only be achieved in practice if all three phases are exactly equal in length.)
It’s worth pointing out that the only thing we have improved here is frame *throughput*–the total number of frames per second that the system can render. This approach does nothing to improve frame *latency*, or the total time that elapses between the time some change happens in the game, and the time it appears onscreen. This might be one reason to avoid this approach, if latency is more important than throughput. However, we’re still talking about a total latency that’s usually less than 100ms or so, which is faster than human response time anyway; and most applications (including games) can tolerate a small amount of latency like this in exchange for a smooth, fast frame rate.
In order for all of this to work, Panda has to do some clever tricks behind the scenes. The most important trick is that there need to be three different copies of the scene graph in different states of modification. As your App process is moving nodes around for frame 3, for instance, Cull is still analyzing frame 2, and must be able to analyze the scene graph *before* anything in App started mucking around to make frame 3. So there needs to be a complete copy of the scene graph saved as of the end of App’s frame 2. Panda does a pretty good job of doing this efficiently, relying on the fact that most things are the same from one frame to the next; but still there is some overhead to all this, so the total performance gain is always somewhat less than the theoretical 3x speedup. In particular, if the application is already running fast (60fps or above), then the gain from parallelization is likely to be dwarfed by the additional overhead requirements. And, of course, if your application is very one-sided, such that almost all of its time is spent in App (or, conversely, almost all of its time is spent in Draw), then you will not see much benefit from this trick.
Also, note that it is no longer possible for anything in App to contact the graphics card directly; while App is running, the graphics card is being sent the drawing commands from two frames ago, and you can’t reliably interrupt this without taking a big performance hit. So this means that OpenGL callbacks and the like have to be sensitive to the threaded nature of the graphics pipeline. (This is why Panda’s interface to the graphics window requires an indirect call: base.win.requestProperties(), rather than base.win.setProperties(). It’s necessary because the property-change request must be handled by the draw thread.)
Early adopters are invited to try this new feature out today, before we formally release 1.8. It’s already available in the current buildbot release; to turn it on, see the new manual page on the subject. Let us know your feedback! There are still likely to be kinks to work out, so we’d love to know how well it works for you.
Excellent. I see this helping some of my projects, but I have one thing that I don’t know how it will work:
If I want to render one shot textures, how is that effected by pipelining? I have for example some rather bad (in my opinion) code here: ( https://github.com/Craig-Macomber/Panda3D-Terrain-System/blob/master/textureRenderer.py ) that adds a render texture, activates a buffer, waits a frame, and deactivates the buffer and sends the texture off to a callback.
Could graphicsBuffer have an optional callback for use with setOneShot that it will call when the texture is ready? (And perhaps a second optional callback for when a ramImage is ready if requested) While it is true that using the texture before its done (the frame after calling setOneShot) would work (since it would be done by the time the frame that needed it gets to draw), makeRamImage can’t work since the since in App, its not done yet, and you would have to wait 2 frames.
Even with 1.7.2, setOneShot does not get along with RTMCopyRam (I don’t get a ram image, and makeRamImage returns all black, and thats why I didn’t use setOneShot in the code I linked earlier). A better API that supported pipelining properly here, and having it actually work properly would be great.
Hmm, it’s a good point, and I haven’t thought all the way through these issues yet. But first, I think setOneShot() needs to work the way it is intended, and should return a ram image in the case of RTMCopyRam. Also, makeRamImage() should work as intended also, which means it should wait the requisite number of frames before it returns (but when it does return, it should have the texture available). I *could* add a callback feature to setOneShot, but this is a little bit complicated; and you could also just spawn a task that checks tex.hasRamImage() each frame and waits for it to return true.
I didn’t think of waiting for hasRamImage. If I wait for tex.hasRamImage() with setOneShot(), it waits forever (I tried in a hard loop with base.graphicsEngine.renderFrame() and polling every frame with a task: same result both ways). If I manually leave the buffer active for one frame, hasRamImage returns true as expected on the second frame (usally, unless I get the issue below). So I guess its a bug with oneShot rendering, and other than that, the approach you suggested (polling every frame for a ramImage) seems to work, and meets my needs. I think it could work with pipelining that way too.
Occasionally I still get the deadlock waiting for hasRamImage, but it only happens when I do a flushing through generating terrain tiles after I’ve been running for a while (how that breaks my texture renderer is not yet clear). Odd.
Please see http://www.panda3d.org/forums/viewtopic.php?t=12009 for a followup question.
David, when you say that threading is now enabled by default, is it enabled even when ‘threading-model Cull/Draw’ is disabled (ie., commented out in config.prc)? Are we free to access Panda objects now using normal python threads?
Yes, even if you don’t set the threading-model, the current Panda builds (and the upcoming 1.8 build) are compiled to support true threads, so you may now use normal Python threads. I still recommend using the stdpy.threading module (which also will create true threads instead of simulated threads now), for greater compatibility across Panda3D versions, and because it supports PStats a little better, but this is no longer a requirement; you may use the normal python threading module if you prefer. Standard disclaimers about race conditions apply. Most Panda objects should be internally self-protected against mutual access, but there are a few that are not.
It’s great to see how the development is going.
I would like to ask a favor, it’s a suggestion actualy, please update the blog more frequently, the post before this was 1 year ago.
Thanks for making panda3d even better!
Cool news, drwr. Do we still benefit if we let Twisted control the event loop?
I know that by this approach the framerate is potentially improved, but the bottleneck in a game design is for most of the part in the ‘App’ frame. If we don’t develop a faster way to do it the framerate remain almost equal to the previous versions.
Paralleling the work is a great innovation in the framework and i like it.
There’s some way to further parallelize some calculation in the app frame ? Like making some threaded functions ?
This comment has nothing to do with the topic. It has to do with “newbie experience”.
I just DL’ed SDK&runtime for macOS. When I tried to find samples in /usr/share/…, there is no panda3D folder.
Where can I get samples? Where are they? Is this manual for linux & windows only?
… and How do I uninstall SDK?